Overview
We present a speech interaction dialogue dataset called InteractSpeech, which designed to enable end-to-end speech language models such as GPT-4o to listen and speak simultaneously. Currently, speech dialogue models lack the ability to interact with humans in real-time spoken scenarios, such as handling interruptions when generated content is unsatisfactory or when new ideas arise. To address this, we have created a 150-hour English interactive dialogue dataset consisting of 90000 dialogue texts to facilitate more realistic and interactive conversational scenarios. On one hand, we used prompt programming on text dialogue datasets to prompt language models to generate corresponding interactive texts, and then employed advanced speech synthesis models to produce dual-track audio clips according to various requirements. On the other hand, we utilized publicly available internet dialogue data, applying speaker overlap detection and voice consistency models to filter interactive segments in speech dialogues. In our experiments, we verified the validity of interactive texts by fine-tuning LLaMA3-8B using LoRA on InteractSpeech.
Processing Pipeline
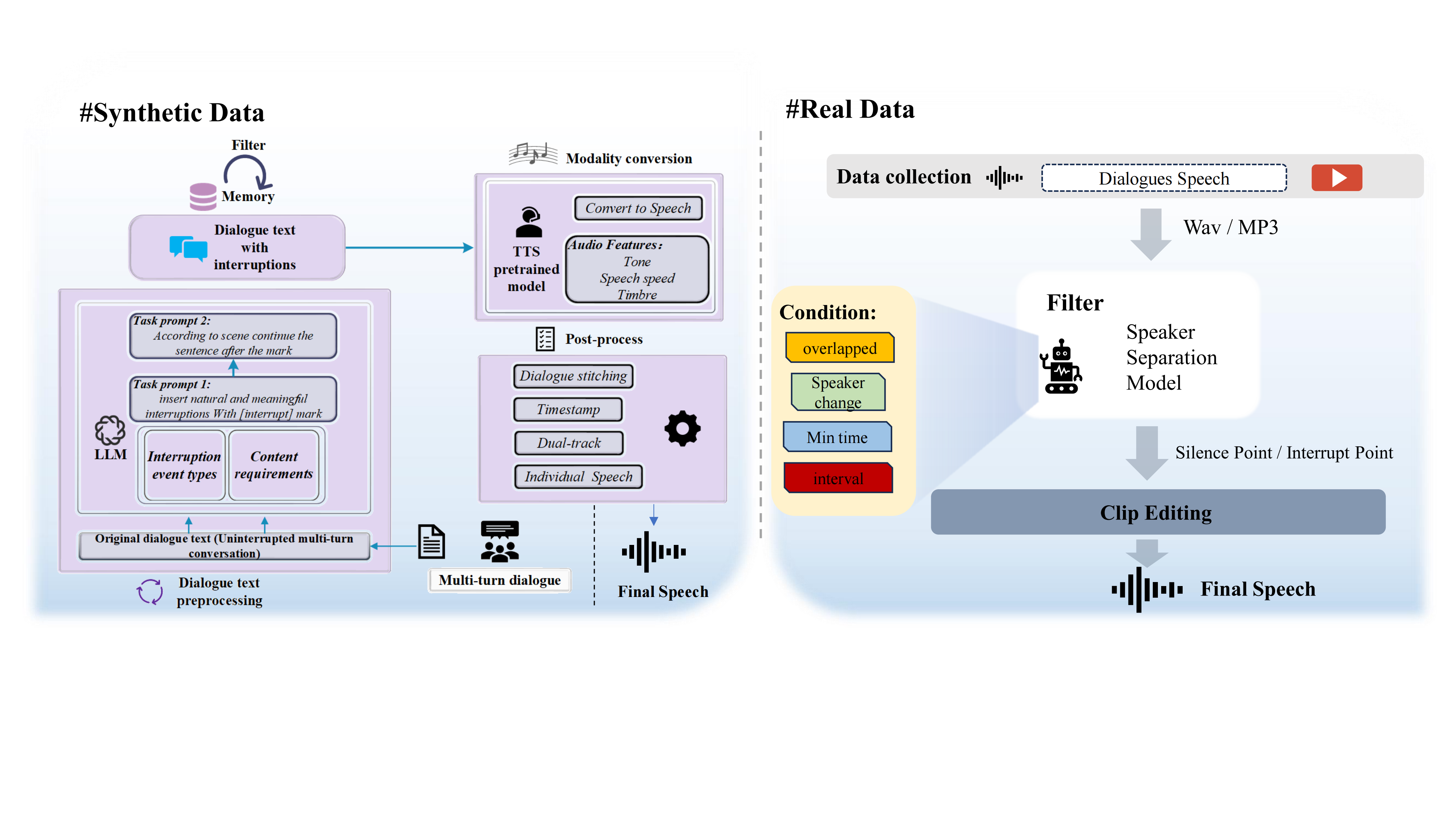
Figure 1. The overall pipeline of InteractSpeech.
Figure (1) illustrates the overall pipeline of InteractSpeech.InteractSpeech combines synthetic and real-world speech to provide a rich variety of interruption scenarios. For the synthetic part, we process the original conversations into interruption scenarios through GPT-4o based on high-quality textual dialog data such as SODA, Dialogsum, PLACES, and MultiWOZ 2.2, and convert them into the speech by using the sota text-to-speech model and organize it into two audio formats, a separate audio format for each speaker, and a dual-track audio format for the complete conversation. The synthetic part in the InteractSpeech contains about 8000 scene dialogs and the total duration is about 112 hours. We pay special attention to the authenticity of the dialogs, and strictly control the frequency of interruptions to avoid frequent interruptions destroying the fluency of the dialogs. Each speaker's utterances were timestamped to ensure precise voice dialogue alignment. The synthetic data is accompanied by transcribed text, timestamps, and speech, so that users can choose to use them according to their different requirements. For the real part, we got about 38 hours of speech about dialogue and processed them through our unique filtering mechanism. In addition, we also provide one hour of manually labeled test set with precisely timestamped interruptions to test the model performance. At the same time, short intonations or affirmations (e.g., “ok”, “yeah”) that are common in real life are not considered as interruptions, and are kept as negative samples for model differentiation to enhance the robustness of the model.
Complete Prompts
First Prompt Template
Please adapt the dialogue into a version that includes interruption scenarios according to the requirements and dialogue content provided below. Strictly follow the following requirements: 1. Mark the interruption position: When the other party has not finished speaking or the key information has not been expressed, choose the right time to interrupt and ensure the diversity of interruption position. Just add the [interrupt] mark after the interrupted word. Avoid interrupting when the other party is almost finished or about to finish. 2. The inserted interruption must be highly relevant to the context and the topic of the conversation, and help to promote the in-depth conversation or clarify key issues. Ensure that the transition of the interruption is natural. 3. After the interruption, the interrupter is not aware of the content that the other party originally did not finish. The unfinished content should be unrelated to the interruption event, and choose whether to mention it again based on the scenario to ensure that the logic is correct and in line with the real scene. 4. The number of interruptions should not exceed two times to ensure the naturalness and fluency of the conversation. 5. Make sure each interruption is meaningful and valuable, and the content is not repeated. Keep the content and tone consistent with the character identity. Example: A: At yesterday's meeting, we discussed the new project plan and decided to start implementing it next quarter. This plan mainly involves resource allocation and team collaboration. We hope to [interrupt]... B: Sorry to interrupt, I just thought of a question, about our existing budget, is it enough to support the implementation of this plan? A: This plan does need more funding, but we have also considered some additional funding sources. However, I haven't mentioned our use of automation tools yet [interrupt]... B: Automation tools are certainly important, but I am more concerned about whether our team's current skills can match the requirements of these tools. Output requirements: Only output the modified and interrupted conversation content, do not output any other content. Strictly follow the following format: A: [Conversation content] B: [Conversation content]
Second Prompt Template
Please complete the sentence with the interruption mark [interrupt] according to the content of the conversation to ensure the naturalness and logical coherence of the conversation. Requirements: 1. Fill in the sentence after the interruption mark [interrupt] reasonably to make the conversation flow naturally. The continuation must be meaningful. 2. Ensure that the continued conversation is natural and fluent, in line with the actual scene and interpersonal communication norms. 3. Keep the [interrupt] mark during the continuation process, and treat the subsequent content as unspoken content. The interrupter is unaware of these contents. Example: Before continuing: A: At yesterday's meeting, we discussed the new project plan and decided to start implementing it next quarter. We hope to [interrupt]... B: Sorry to interrupt, I just thought of a question, about our existing budget, is it enough to support the implementation of this plan? Continuation: A: We hope to [interrupt] improve resource utilization in this process and manage our resources more effectively. B: Sorry to interrupt, I just thought of a question, about our existing budget, is it enough to support the implementation of this plan? Output requirements: Only output the content of the continued conversation, strictly in the following format: A: [Conversation content] B: [Conversation content]
Dialogue Demo
Scenario 1 - Full Conversation (Stereo)
Dialogue Transcript with Timestamps:
A (0s - 5.212s): Thank you so much for everything, Miss Smith. I really appreciate all that you've done for [interrupt] helping me prepare for these exams.
B (4.759s - 11.388s): Oh, it was nothing. But before you go on, I wanted to ask—how are you feeling about the upcoming exams?
A (11.388s - 18.679s): I'm a bit nervous, to be honest. But your support has really helped me. I was just saying that you've helped me more than you know.
B (18.679s - 23.973s): I'm glad to hear that. Remember, you're a great student, Amar, and I have full confidence in you.
A (23.973s - 25.123s): Thank you, Miss Smith.
Scenario 1 - Speaker 1
Scenario 1 - Speaker 2
Scenario 2 - Full Conversation (Stereo)
Dialogue Transcript with Timestamps:
A (0s - 1.834s): Wow, we look amazing!
B (1.834s - 5.549s): I know, right? We should totally walk around like [interrupt] we own the place and let everyone see how incredible we look.
A (5.096s - 11.829s): Actually, before we do that, do you think we should take some pictures first? I mean, we need to capture this moment!
B (11.829s - 15.649s): Absolutely! But after that, let's go show everyone how glamorous we are!
A (15.649s - 17.321s): I feel like a movie star!
B (17.321s - 20.897s): Me too! We should walk around like we're on a [interrupt] runway, making sure everyone notices our stunning outfits.
A (20.443s - 27.154s): Wait, let's make sure we have the perfect poses down before we start. We need to nail that red carpet look!
B (27.154s - 30.010s): Good idea! Let's start strutting our stuff!
Scenario 2 - Speaker 1
Scenario 2 - Speaker 2